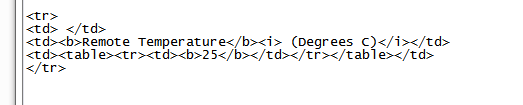Очень слабоват в Питоне, и не могу разобраться - почему код не работает ?
Суть такова - скачивается html-страничка, сохраняется на жесткий диск как текстовый файл, и потом уже в нем происходит поиск подстроки. Вся завтыка в том, что несмотря на то, что это слово есть в тексте, оно не находится.
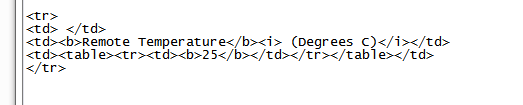
Сначала я сделал так (ищется словосочетание Remote Temperature):
import urllib.request
urlibp = 'qqq.www.eee.rrr/index.htm' здесь указан ip-адрес - для вопроса он не важен
def get_data(url):
remtemp = 0
urllib.request.urlretrieve(url, filename = 'ibp.txt') #
infile = open('ibp.txt', 'r')
lines = infile.readlines()
for i in range(len(lines)):
line = lines[i]
if 'Remote Temperature' in line:
without_space = line[i+1].strip()
remtemp = float(without_space[21:-27])
else:
break
infile.close()
print (("Remote Temperature: ") + str(remtemp))
get_data(urlibp)
При запуске текстовый файл создается, но функция возвращает Remote Temperature: 0 - значение не поменялось.
Тогда решил попробовать метод find(), подправил код, чтобы найти индекс слова Remote:
import urllib.request
urlibp = 'qqq.www.eee.rrr/index.htm'
urllib.request.urlretrieve(urlibp, filename = 'ibp.txt')
infile = open('ibp.txt', 'r')
lines = infile.readlines()
str1 = ' '.join(lines)
ind = str1.find('Remote')
print (str(ind))
В этом случае возвращается значение "-1", т. е. find не нашел "Remote". После этого меня и посетила мысль - правильно ли я действую ? Подскажите пожалуйста - где ошибка ?
ОС - Windows 7, Python 3.2