Подскажите пожалуйста универсальный, стабильный, не очень сложный алгоритм для поиска ближайшей прямоугольной области, содержащей слово, на изображении от заданной точки.
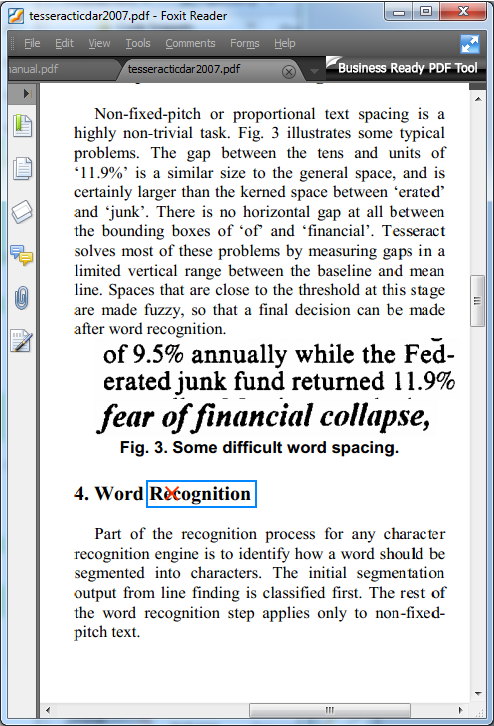 Входными данными
Входными данными является точка X, Y (на рисунке отмечена красным крестиком).
Выходными данными является прямоугольник Left, Top, Width, Height (на рисунке отмечен голубым цветом).
Универсальность подразумевает под собой работу с любыми размерами, цветами шрифтов и как можно большим количеством типов шрифтов.
На данный момент реализован алгоритм, идея которого заключается в подсчете светлых пикселей в столбцах и строках несколько раз. Но он нуждается в доработке и подборке коэффициентов.
У кого-нибудь есть другие идеи? Как сегментация слов и картинок реализована в OCR движках?




 Средний
Средний
 Средний
Средний
 Средний
Средний




