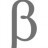Здравствуйте сообщество. Попытки разобраться с многопроцессорностью на питоне привели к серьезной загвоздке. Буду очень признательна за любую помощь в разборе проблемы, или за рекомендации по исправлению кода.
В программе для математических расчетов использую часть с multiprocessing. Параллельный блок кода выглядит так:
worker_count = multiprocessing.cpu_count()
jobs = []
print "---> Starting multiprocessing #", series_number
for i in xrange(worker_count):
s = solver.get_solution(copied_system)
p = multiprocessing.Process(target=combinatorial_set.find_nearest_set_point, args=(s, result_queue))
jobs.append(p)
p.start()
print p
for w in jobs:
w.join()
print w
results = []
while not result_queue.empty():
results.append(result_queue.get())
for i in xrange(len(res)):
print results[i], is_solution(copied_system, results[i])
if is_solution(copied_system, results[i]):
func_value = f(results[i])
experiment_valid_points[func_value] = results[i]
#End of parallel
print "---> End of multiprocessing #", series_number
Вот что должен был делать данный код:
Проводится серия экспериментов. В рамках каждого эксперимента совершаются такие действия
1. Запуск эксперимента.
2. Генерация точек (s) в некоторой области. Количество точек = количеству ядер.
3. Запуск для каждой точки нахождения минимума функции. Эта часть выполняется параллельно.
4. Сбор результатов.
5. Выбор из сгенерированых точек лучшей.
6. Пересчет области для генерации.
7. Переход к новому эксперименту.
А вот что получается:
На практике данный код работает очень нестабильно. На одних и тех же данных могут быть следующие ситуации.
1. Первая "идеальная": в рамках каждого эксперимента запускается 4 python.exe которые каждый загружают ~ по 25% ЦП. После окончания эксперимента 3 из этих четырех процессов умирают и все начинается с начала.
2. Вторая "хуже" : в рамках каждого эксперимента запускается 4 python.exe но они выполняются псевдопараллельно. В мониторе ресурсов видно 4 процесса python.exe по одному потоку в каждом. В один момент времени работает всегда только один, остальные прерваны пока до них не дойдет очередь.
3. Третий "худший" : в консоли все 4 процесса отписываются Process(Process-i, started), но ни в диспетчере задач, ни в мониторе ресурсов 4 процессов нет. Есть только 1 python.exe, который загружает ~ 25% ЦП и не понятно что считает. Естественно работа дальше не идет, так как нужно дождаться завершения работы всех четырех процессов, а их просто не существует.
Заранее спасибо за ответы.


 Простой
Простой